Yet Another XOR Tree Problem
Subtask 1:
Any bruteforce solution should pass.
Subtask 2:
In each , treat node as the root node of the tree. Run a BFS/DFS from node and track the nodes that lie on the simple path between node and node . You can do it by managing a array, where . You should also calculate for all node while running BFS/DFS. The rest is for the solver to solve.
Subtask 3:
If you’re not familiar with finding maximum using Trie data structure, read this at first.
Let’s take an arbitrary node as the root of the tree. In the below example, we’ll treat node as the root node.
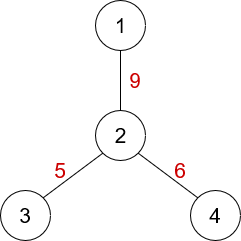
The weights of the edges are written in red colour. Here, . So, , which is clearly the value of . That is to say, we can write as .
Let, the Lowest Common Ancestor (LCA) of node and node is node . Now in queries, we can split the queries into two separate queries: and , where means the maximum value of such that node lies on the simple path connecting node and node ; is node or any ancestor of node . The maximum of these two splitted queries will be our desired answer for the real query.
To answer , we need to precalculate for all node at first. After that, we can build a trie only using the values of , where is node or any ancestor of node . Then it comes down to the normal trie problem stated at the beginning of the editorial (subtask 3). To ensure that we don’t search in a trie node created by only the ancestors of node , we may track the maximum dfs discovery time in trie nodes or do similar kinds of things.
As building trie using the values of for each node will be a huge memory-consuming task, we need to use Persistent Trie data structure.
This problem can also be solved using a normal Trie data structure by answering the queries offline. The above concept is helpful in this approach too.
Setter’s Sol: https://pastebin.com/Xdn7SrDD